


Building a super human driving agent
Based on the talk presented by Harald Schäfer


Openpilot is a relatively mature open-source project for L2 assisted driving systems introduced by Comma.ai, which implements conventional assisted driving functions including Adaptive Cruise Control (ACC), Automated Lane Centering (ALC), Forward Collision Warning (FCW) and Lane Keeping Assist (LKA). It is designed to be compatible with over 250 types of vehicles. Users can enjoy the experience of assisted driving by installing the aftermarket kit on their car in a few steps. The sections below explain some of the research ideas from their company.
What is a real self-driving car?
Crashes less than an average human
Isn't slow and gets you anywhere under all conditions
Classical Approach
The approach by almost all self-driving companies is

Sensor Data Collection (or Fusion) Collect data via sensors such as cameras, lidars etc.
Perception Read sensor data and perceive what the environment contains.
Planning Plan the path based on the environmental conditions
Control Execute the plan
Most robotics application development follows this strategy. It decouples the system, giving more control over the robot's actions in the real world and aids in troubleshooting.
End-to-End (E2E) Approach
The E2E approach fuses the perception and planning components into a machine-learning model. In the E2E we have,

Sensor Data Collection (or Fusion)
Planning
Controls
Why End-of-End (E2E)?
The important question is why we need E2E, especially in the self-driving space.
Consider a self-driving car looking at the following image

The classical planner would be
Stop at traffic lights
Dont hit cars
Dont hit pedestrian
Stay in lane
What does it mean? you need to keep a safe distance from the pedestrian, may swerve slights towards your right, but almost make sure we don't go off lane markings.

Now let's change the scene a little bit and a child bouncing the ball. This changes everything. Now we need a super careful, perhaps even slow down considerably and change lanes and take extra precautions. The perception layer is trained to look "PERSON" and not distinguish between a person from a baby. We can add this to the training data. What if there is an old man? We can never obtain a comprehensive list of such objects and hence are not scalable.
Furthermore, the lateral control pipeline for self-driving cars can be divided into five main steps: lane detection, depth estimation, tracking, path planning, and vehicle control. The pipeline takes as input RGB images from the car's cameras and outputs a desired steering angle or torque that is sent to the car's steering actuator. This article explains the issues involved in every step.
What if we feed data to a large ML model and let it output the path?
Comma skips object detection, depth estimation, etc to directly output trajectory to be followed by the vehicle. Read more about this in their blog post here. This path is then tracked by a conventional control stack maintained by their team.
So what do we need for E2E?
What is the plan for E2E? First, get large data. not just any data, data from humans. Currently, humans are the best drivers, and modeling a machine-learning model based on humans and slightly correcting for bad behavior seems to be the best policy
What is the cheapest way to get large data?
Crowd Sourcing! While other self-driving car companies raise millions, buy a fleet of cars and obtain data, comma cleverly outsourced the data to the passionate and early adopters of the technology.
Ground Truth
Once you have data, you have to create the ground truth for the data. Then, you can develop a model which can learn from the ground truth that we have established and draw paths for the unseen videos that are captured by the comma device. We need what is called a "localizer". Why localizer? It answers the following questions. :- Where am I? Where I am looking? Where should I go? Where did I go? One of the best ways to localize a self-driving car is to receive data from GPS, triangulate, and locate the position of you (or your car). It's only an approximation and usually errors by an order of meters. The comma team developed an open-source library called Laika. Laika not only gets GPS data but uses Doppler shift from each GPS satellite to accurately present the location and speed of the car. More details can be found here The shortcoming of the GPS is fixed by taking the corrected GPS measurements from the Laika library and along with IMU, camera data is fused and fed to a Kalman filter to further enhance the prediction of the position and velocity of the vehicle. The library that helps in this is Rednose. Now that localizer is good and we can accurately predict how humans drive, we are good to train ML!
Machine Learning
Comma used the efficient net with 2 frames of video to predict the path that the humans would take. Additional details in their blog post here
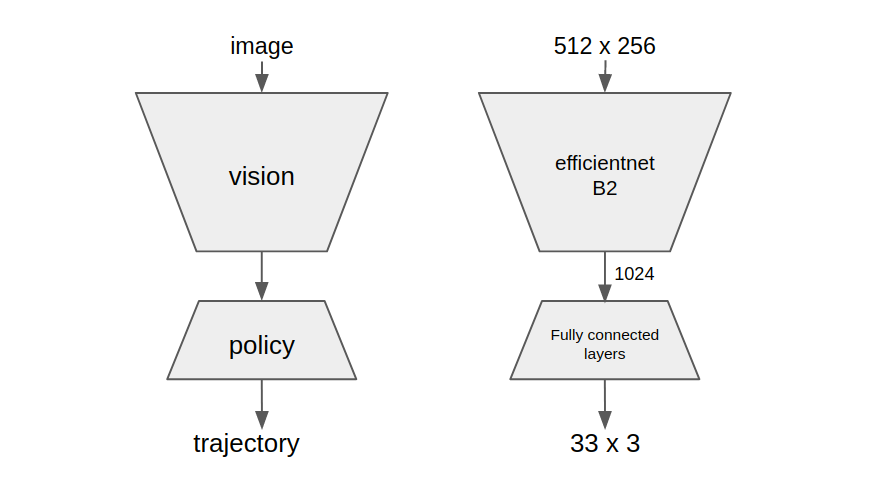
Testing and Interpreting Results
When they tried on the real self-driving car it failed terribly. So they opted for the simulator. To get a good simulator means to have diverse conditions, the one that meets most if not all conditions of real-world driving. The clever way of doing this is to take a real video of human driving and modify the video slightly to make the model think its a not a real video but a simulation.
Problem with that human cloning
The model in the simulator (and in the real world) is affected by disturbances. that throw the car off the predicted path. First, as comma.ai has figured, the model just learns and predicts the human drivers’ most likely behavior. In datasets collected from the real world, the drivers just keep the vehicle going straight most of the time, and avoid any possible bad behavior, such as dangerous driving and traffic offence. In this way, the model will not even have the chance to learn how to recover from mistakes. For example, if we manually feed a video sequence where the vehicle is going over the center line, which of course is a kind of dangerous driving, the model is likely to predict a trajectory that keeps going straight, instead of returning to the correct line.
Second, we notice that it may introduce a kind of feature leakage. Under certain circumstances, if the vehicle is currently speeding up, the model will predict a longer and faster trajectory and vice-versa. Also, if the vehicle is turning left or right, the model will predict a corresponding trajectory that turns left or right. This suggests that the model is learning from the drivers’ driving intentions rather than the road characteristics. A typical scenario that reveals this problem is starting-and-stop according to traffic lights. The model may decide to slow down long before it sees the red light or the stop line. Then, when the car is slowly starting to move before the red light turns green, the model may decide to speed up quickly. This makes us believe there is a certain kind of temporal feature leakage.
Allowing a non-well-trained vehicle on the road based on its predicted trajectory is too dangerous and thus not practical. There are two solutions. The first one is introduced in comma.ai's blog. We can simulate closed-loop training and testing through the WARP mechanism, making the images collected from one perspective look like being collected from a different perspective. The second one is to train and test the model completely in a simulator. However, neither of the solutions is perfect, for the WARP mechanism will introduce image artifacts while the existing simulators fail to render realistic images. Solution? TRAIN in the simulator! Using the simulator not for inference but to train the model gives us the ability to influence model behavior. We can introduce various kinds of disturbances (internal and external) and then ask the model to follow human policy. Well, there is 1 minor thing to consider. what if there are situations where are more than 1 safe answer? By far the most popular ones are lane changes. Lane changes needs context, and the comma team hand-labeled a few scenarios and provided the model for some context for the lane changes. Being a comma user myself, it never suggests a lane change, so it always chooses a straight path unless a turn indicator is triggered by the driver.
What next?
Until this point, we are talking about lateral movements. longitudinal e2e (gas and brake) is the next step in the evolution of the policy. [Update: there are several cars already with e2e support]
References
Self-driving 2.0. The only way to solve self-driving | by Ilsu Park | Mars Auto